by Guido Sanguinetti
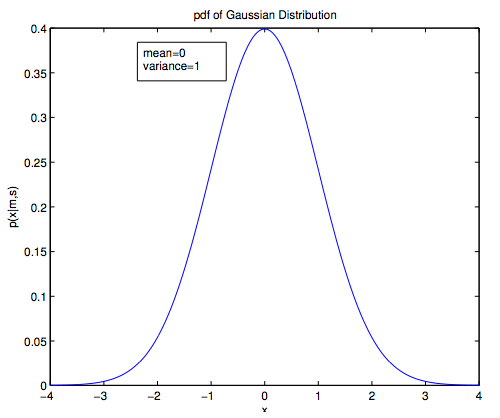
1-D Gaussian distribution
1-D Gaussian with zero mean and unit variance ($\mu = 0$, $\sigma^2 = 1$):
The multidimensional Gaussian distribution
- The $d$-dimensional vector $X$ is multivariate Gaussian if it has a probability density function of the following form:1
-
The pdf is parameterized by the mean vector $M$ and the covariance matrix $\sum$.
-
The 1-D Gaussian is a special case of this pdf.
-
The argument to the expontial $0.5(X-M)^T{\sum}^{-1}(X-M)$ is referred to as a quadratic form.
Covariance matrix
- The mean vector $M$ is the expectation of $X$:
- The covariance matrix $\sum$ is the expectation of the deviation of $X$ from the mean:
- ${\sum}$ is a $d \times d$ symmetric matrix:
- The sign of the covariance helps to determine the relationship between two components:
- If $X_j$ is large when $X_i$ is large, then $(X_j-M_j)(X_i-M_i)$ will tend to be positive;
- If $X_j$ is small when $X_i$ is large, then $(X_j-M_j)(X_i-M_i)$ will tend to be negative.
The covariance matrix is not scale-independent: Define the correlation coefficient:
- Scale-independent (i.e. independent of the measurement units) and location-independent, i.e.:
- The correlation coefficient satisfies $-1 \le \rho \le 1$, and
Parameters estimation
It is possible to show that the mean vector $\widehat{M}$ and covariance matrix $\widehat{\sum}$ that maximize the likelihood of the training data are given by:
The mean of the distribution is estimated by the sample mean and the covariance by the sample covariance.\rho
-
M here is capital $\mu$, stands for multidimensional vector. ↩